Note: Use of this Llama-2 model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the website and accept the license before requesting access.
We are actively enhancing this blueprint to incorporate improvements in observability, logging, and scalability aspects.
Training a Llama-2 Model using Trainium, Neuronx-Nemo-Megatron and MPI operator
Welcome to the comprehensive guide on training the Meta Llama-2-7b model on Amazon Elastic Kubernetes Service (EKS) using AWS Trainium, Neuronx-Nemo-Megatron, and the MPI Operator.
In this tutorial you will learn how to run multi-node training jobs using AWS Trainium accelerators in Amazon EKS. Specifically, you will pretrain Llama-2-7b on 4 AWS EC2 trn1.32xlarge instances using a subset of the RedPajama dataset.
What is Llama-2?
Llama-2 is a large language model (LLM) trained on 2 trillion tokens of text and code. It is one of the largest and most powerful LLMs available today. Llama-2 can be used for a variety of tasks, including natural language processing, text generation, and translation.
Although Llama-2 is available as a pretrained model, in this tutorial we will show how to pretrain the model from scratch.
Llama-2-chat
Llama-2 is a remarkable language model that has undergone a rigorous training process. It starts with pretraining using publicly available online data.
Llama-2 is available in three different model sizes:
- Llama-2-70b: This is the largest Llama-2 model, with 70 billion parameters. It is the most powerful Llama-2 model and can be used for the most demanding tasks.
- Llama-2-13b: This is a medium-sized Llama-2 model, with 13 billion parameters. It is a good balance between performance and efficiency, and can be used for a variety of tasks.
- Llama-2-7b: This is the smallest Llama-2 model, with 7 billion parameters. It is the most efficient Llama-2 model and can be used for tasks that do not require the highest level of performance.
Which Llama-2 model size should I use?
The best Llama-2 model size for you will depend on your specific needs. and it may not always be the largest model for achieving the highest performance. It's advisable to evaluate your needs and consider factors such as computational resources, response time, and cost-efficiency when selecting the appropriate Llama-2 model size. The decision should be based on a comprehensive assessment of your application's goals and constraints.
Performance Boost While Llama-2 can achieve high-performance inference on GPUs, Neuron accelerators take performance to the next level. Neuron accelerators are purpose-built for machine learning workloads, providing hardware acceleration that significantly enhances Llama-2's inference speeds. This translates to faster response times and improved user experiences when deploying Llama-2 on Trn1/Inf2 instances.
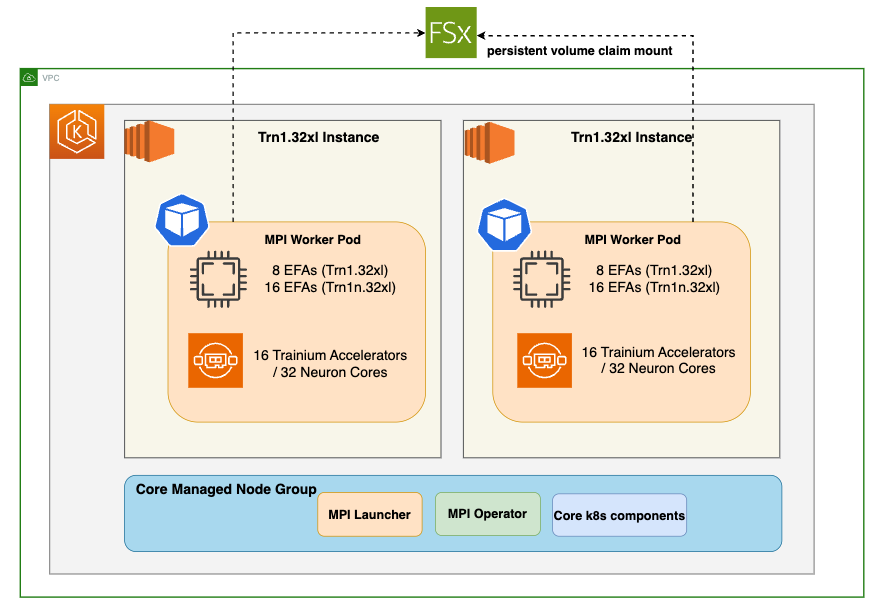
Solution Architecture
In this section, we will delve into the architecture of our solution.
Trn1.32xl Instance: This is an EC2 accelerated instance type that is part of the EC2 Trn1 (Trainium) instance family, optimized for machine learning training workloads
MPI Worker Pods: These are Kubernetes pods configured for running MPI (Message Passing Interface) tasks. MPI is a standard for distributed memory parallel computing. Each worker pod runs on a trn1.32xlarge instance which is equipped with 16 Trainium accelerators and 8 Elastic Fabric Adapters (EFAs). EFAs are network devices that support high-performance computing applications running on Amazon EC2 instances.
MPI Launcher Pod: This pod is responsible for coordinating the MPI job across the worker pods. When a training job is first submitted to the cluster, an MPI launcher pod is created which waits for the workers to come online, connects to each worker, and invokes the training script.
MPI Operator: An operator in Kubernetes is a method of packaging, deploying, and managing a Kubernetes application. The MPI Operator automates the deployment and management of MPI workloads.
FSx for Lustre: A shared, high-performance filesystem which is well suited for workloads such as machine learning, high performance computing (HPC), video processing, and financial modeling. The FSx for Lustre filesystem will be shared across worker pods in the training job, providing a central repository to access the training data and to store model artifacts and logs.
Deploying the Solution
Steps to train Llama-2 using AWS Trainium on Amazon EKS
Note: This post makes use of Meta’s Llama tokenizer, which is protected by a user license that must be accepted before the tokenizer files can be downloaded. Please ensure that you have access to the Llama files by requesting access here.
Prerequisites
👈Distributed training
Once the EKS Cluster is deployed, you can proceed with the next steps of building neuronx-nemo-megatron container image and pushing the image to ECR.
Build the neuronx-nemo-megatron container image
Navigate to examples/llama2 directory
cd examples/llama2/
Run the 1-llama2-neuronx-pretrain-build-image.sh script to build the neuronx-nemo-megatron container image and push the image into ECR.
When prompted for a region, enter the region in which you launched your EKS cluster, above.
./1-llama2-neuronx-pretrain-build-image.sh
Note: The image building and pushing to ECR will take ~10 minutes
Launch and connect to a CLI pod
In this step we need access to the shared FSx storage. To copy files to this storage, we’ll first launch and connect to a CLI pod running the neuronx-nemo-megatron docker image that you created above.
Run the following script to launch the CLI pod:
./2-launch-cmd-shell-pod.sh
Next, periodically run the following command until you see the CLI pod go into ‘Running’ state:
kubectl get pod
Once the CLI pod is ‘Running’, connect to it using the following command:
kubectl exec -it cli-cmd-shell -- /bin/bash
Download the Llama tokenizer and Redpajama dataset to FSx
From within the CLI pod, we’ll download the Llama tokenizer files. These files are protected by Meta's Llama license, so you will need to run the huggingface-cli login command to login to Hugging Face using your access token. The access token is found under Settings → Access Tokens on the Hugging Face website.
huggingface-cli login
When prompted for your token, paste-in the access token and hit ENTER.
Next, you download the llama7-7b tokenizer files to /shared/llama7b_tokenizer by running the following python code:
python3 <<EOF
import transformers
tok = transformers.AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
tok.save_pretrained("/shared/llama7b_tokenizer")
EOF
Next, download the RedPajama-Data-1T-Sample dataset (a small subset of the full RedPajama dataset that contains 1B tokens).
While still connected to the CLI pod, use git to download the dataset
cd /shared
git clone https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T-Sample \
data/RedPajama-Data-1T-Sample
Tokenize the dataset
Tokenize the dataset using the preprocessing script included with neuronx-nemo-megatron. This preprocessing step will take ~60 minutes to run on a trn1.32xl instance.
cd /shared
# Clone the neuronx-nemo-megatron repo, which includes the required scripts
git clone https://github.com/aws-neuron/neuronx-nemo-megatron.git
# Combine the separate redpajama files to a single jsonl file
cat /shared/data/RedPajama-Data-1T-Sample/*.jsonl > /shared/redpajama_sample.jsonl
# Run preprocessing script using llama tokenizer
python3 neuronx-nemo-megatron/nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py \
--input=/shared/redpajama_sample.jsonl \
--json-keys=text \
--tokenizer-library=huggingface \
--tokenizer-type=/shared/llama7b_tokenizer \
--dataset-impl=mmap \
--output-prefix=/shared/data/redpajama_sample \
--append-eod \
--need-pad-id \
--workers=32
Modify dataset and tokenizer paths in the training script
Note: When we later launch our training jobs in EKS, the training pods will run the training script from within neuronx-nemo-megatron/nemo/examples directory on FSx. This is convenient, because it will let you modify your training script directly on FSx without requiring that you rebuild the neuronx-nemo-megatron container for every change.
Modify the test_llama.sh script /shared/neuronx-nemo-megatron/nemo/examples/nlp/language_modeling/test_llama.sh to update the following two lines. These lines tell the training pod workers where to find the Llama tokenizer and the dataset on the FSx filesystem.
You can use any common text editor such as nano or vim to make these changes.
Run:
nano /shared/neuronx-nemo-megatron/nemo/examples/nlp/language_modeling/test_llama.sh
Before changes:
: ${TOKENIZER_PATH=$HOME/llamav2_weights/7b-hf}
: ${DATASET_PATH=$HOME/examples_datasets/llama_7b/book.jsonl-processed_text_document}
After changes:
: ${TOKENIZER_PATH=/shared/llama7b_tokenizer}
: ${DATASET_PATH=/shared/data/redpajama_sample_text_document}
You can save your changes in nano by pressing CTRL-X, then y, then ENTER.
When you are finished, type exit or press CTRL-d to exit the CLI pod.
If you no longer need the CLI pod you can remove it by running:
kubectl delete pod cli-cmd-shell
We are finally ready to launch our pre-compilation and training jobs!
First, let's check to make sure the MPI operator is functional by running this command:
kubectl get all -n mpi-operator
If the MPI Operator is not installed, please follow the MPI Operator installation instructions before proceeding.
Before we can run the training job, we first run a pre-compilation job in order to prepare the model artifacts. This step extracts and compiles the underlying compute graphs for the Llama-2-7b model and generates Neuron executable files (NEFFs) that can run on the Trainium accelerators. These NEFFs are stored in a persistent Neuron cache on FSx so that the training job can later access them.
Run pre-compilation job
Run the pre-compilation script
./3-llama2-neuronx-mpi-compile.sh
Pre-compilation will take ~10 minutes when using 4 trn1.32xlarge nodes.
Periodically run kubectl get pods | grep compile and wait until you see that the compile job shows ‘Completed’.
When pre-compilation is complete, you can then launch the pre-training job on 4 trn1.32xl nodes by running the following script:
Run training job
./4-llama2-neuronx-mpi-train.sh
View training job output
To monitor the training job output - first, find the name of the launcher pod associated with your training job:
kubectl get pods | grep launcher
Once you have identified the name of the launcher pod and see that it is ‘Running’, the next step is to determine its UID. Replace test-mpi-train-launcher-xxx with your launcher pod name in the following command and it will output the UID:
kubectl get pod test-mpi-train-launcher-xxx -o json | jq -r ".metadata.uid"
Use the UID to determine the log path so you can tail the training logs. Replace UID in the following command with the above value.
kubectl exec -it test-mpi-train-worker-0 -- tail -f /shared/nemo_experiments/UID/0/log
When you are done viewing the logs, you can press CTRL-C to quit the tail command.
Monitor Trainium accelerator utilization
To monitor Trainium accelerator utilization you can use the neuron-top command. Neuron-top is a console-based tool for monitoring Neuron and system-related performance metrics on trn1/inf2/inf1 instances. You can launch neuron-top on one of the worker pods as follows:
kubectl exec -it test-mpi-train-worker-0 -- /bin/bash -l neuron-top
View training job metrics in TensorBoard
TensorBoard is a web-based visualization tool that is commonly used to monitor and explore training jobs. It allows you to quickly monitor training metrics, and you can also easily compare metrics across different training runs.
TensorBoard logs available in the /shared/nemo_experiments/ directory on the FSx for Lustre filesystem.
Run the following script to create a TensorBoard deployment so you can visualize your Llama-2 training job progress:
./5-deploy-tensorboard.sh
Once the deployment is ready the script will output a password-protected URL for your new TensorBoard deployment.
Launch the URL to view your training progress.
When you have opened the TensorBoard interface, choose your training job UID from the left-hand menu, and then explore the various training metrics (ex: reduced-train-loss, throughput, and grad-norm) from the main application window.
Stopping the training job
To stop your training job and remove the launcher/worker pods, run the following command:
kubectl delete mpijob test-mpi-train
You can then run kubectl get pods to confirm that the launcher/worker pods have been removed.