Deploying PostgreSQL Database on EKS using CloudNativePG Operator
Introduction
CloudNativePG is an open source operator designed to manage PostgreSQL workloads Kubernetes.
It defines a new Kubernetes resource called Cluster representing a PostgreSQL
cluster made up of a single primary and an optional number of replicas that co-exist
in a chosen Kubernetes namespace for High Availability and offloading of
read-only queries.
Applications that reside in the same Kubernetes cluster can access the PostgreSQL database using a service which is solely managed by the operator, without having to worry about changes of the primary role following a failover or a switchover. Applications that reside outside the Kubernetes cluster, need to configure a Service or Ingress object to expose the Postgres via TCP. Web applications can take advantage of the native connection pooler based on PgBouncer.
CloudNativePG was originally built by EDB, then released open source under Apache License 2.0 and submitted for CNCF Sandbox in April 2022. The source code repository is in Github.
More details about the project will be found on this link
Deploying the Solution
Let's go through the deployment steps
Prerequisites
Ensure that you have installed the following tools on your machine.
Deploy the EKS Cluster with CloudNativePG Operator
First, clone the repository
git clone https://github.com/awslabs/data-on-eks.git
Navigate into cloudnative-postgres folder and run install.sh script. By default the script deploys EKS cluster to us-west-2 region. Update variables.tf to change the region. This is also the time to update any other input variables or make any other changes to the terraform template.
cd data-on-eks/distributed-databases/cloudnative-postgres
./install.sh
Verify Deployment
Verify the Amazon EKS Cluster
aws eks describe-cluster --name cnpg-on-eks
Update local kubeconfig so we can access kubernetes cluster
aws eks update-kubeconfig --name cnpg-on-eks --region us-west-2
First, lets verify that we have worker nodes running in the cluster.
kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-10-1-10-192.us-west-2.compute.internal Ready <none> 4d17h v1.25.6-eks-48e63af
ip-10-1-10-249.us-west-2.compute.internal Ready <none> 4d17h v1.25.6-eks-48e63af
ip-10-1-11-38.us-west-2.compute.internal Ready <none> 4d17h v1.25.6-eks-48e63af
ip-10-1-12-195.us-west-2.compute.internal Ready <none> 4d17h v1.25.6-eks-48e63af
Next, lets verify all the pods are running.
kubectl get pods --namespace=monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 1 (4d17h ago) 4d17h
kube-prometheus-stack-grafana-7f8b9dc64b-sb27n 3/3 Running 0 4d17h
kube-prometheus-stack-kube-state-metrics-5979d9d98c-r9fxn 1/1 Running 0 60m
kube-prometheus-stack-operator-554b6f9965-zqszr 1/1 Running 0 60m
prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 4d17h
kubectl get pods --namespace=cnpg-system
NAME READY STATUS RESTARTS AGE
cnpg-on-eks-cloudnative-pg-587d5d8fc5-65z9j 1/1 Running 0 4d17h
Deploy a PostgreSQL cluster
First of all, we need to create a storageclass using the ebs-csi-driver, a demo namespace and kubernetes secrets for login/password for database authentication app-auth. Check examples folder for all kubernetes manifests.
Storage
For running a highly scalable and durable self-managed PostgreSQL database on Kubernetes with Amazon EKS and EC2, it is recommended to use Amazon Elastic Block Store (EBS) volumes that provide high performance and fault tolerance. The preferred EBS volume types for this use case are:
1.Provisioned IOPS SSD (io2 or io1):
- Designed for I/O-intensive workloads such as databases.
- Offers consistent and low-latency performance.
- Allows you to provision a specific number of IOPS (input/output operations per second) according to your requirements.
- Provides up to 64,000 IOPS per volume and 1,000 MB/s throughput, making it suitable for demanding database workloads.
2.General Purpose SSD (gp3 or gp2):
- Suitable for most workloads and offers a balance between performance and cost.
- Provides a baseline performance of 3,000 IOPS and 125 MB/s throughput per volume, which can be increased if needed (up to 16,000 IOPS and 1,000 MB/s for gp3).
- Recommended for less I/O-intensive database workloads or when cost is a primary concern.
You can find both storageclass template in examples folder.
kubectl create -f examples/storageclass.yaml
kubectl create -f examples/auth-prod.yaml
As with any other deployment in Kubernetes, to deploy a PostgreSQL cluster you need to apply a configuration file that defines your desired Cluster. CloudNativePG operator offers two type of Bootstrapping a new database:
- Bootstrap an empty cluster
- Bootstrap From another cluster.
In this first example, we are going to create a new empty database cluster using initdbflags. We are going to use the template below by modifying the IAM role for IRSA configuration 1 and S3 bucket for backup restore process and WAL archiving 2. The Terraform could already created this use terraform output to extract these parameters:
cd data-on-eks/distributed-databases/cloudnative-postgres
terraform output
barman_backup_irsa = "arn:aws:iam::<your_account_id>:role/cnpg-on-eks-prod-irsa"
barman_s3_bucket = "XXXX-cnpg-barman-bucket"
configure_kubectl = "aws eks --region us-west-2 update-kubeconfig --name cnpg-on-eks"
---
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: prod
namespace: demo
spec:
description: "Cluster Demo for DoEKS"
# Choose your PostGres Database Version
imageName: ghcr.io/cloudnative-pg/postgresql:15.2
# Number of Replicas
instances: 3
startDelay: 300
stopDelay: 300
replicationSlots:
highAvailability:
enabled: true
updateInterval: 300
primaryUpdateStrategy: unsupervised
serviceAccountTemplate:
# For backup and restore, we use IRSA for barman tool.
# You will find this IAM role on terraform outputs.
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::<<account_id>>:role/cnpg-on-eks-prod-irsa #1
postgresql:
parameters:
shared_buffers: 256MB
pg_stat_statements.max: '10000'
pg_stat_statements.track: all
auto_explain.log_min_duration: '10s'
pg_hba:
# - hostssl app all all cert
- host app app all password
logLevel: debug
storage:
storageClass: ebs-sc
size: 1Gi
walStorage:
storageClass: ebs-sc
size: 1Gi
monitoring:
enablePodMonitor: true
bootstrap:
initdb: # Deploying a new cluster
database: WorldDB
owner: app
secret:
name: app-auth
backup:
barmanObjectStore:
# For backup, we S3 bucket to store data.
# On this Blueprint, we create an S3 check the terraform output for it.
destinationPath: s3://<your-s3-barman-bucket> #2
s3Credentials:
inheritFromIAMRole: true
wal:
compression: gzip
maxParallel: 8
retentionPolicy: "30d"
resources: # m5large: m5xlarge 2vCPU, 8GI RAM
requests:
memory: "512Mi"
cpu: "1"
limits:
memory: "1Gi"
cpu: "2"
affinity:
enablePodAntiAffinity: true
topologyKey: failure-domain.beta.kubernetes.io/zone
nodeMaintenanceWindow:
inProgress: false
reusePVC: false
Once updated, you can apply your template.
kubectl create -f examples/prod-cluster.yaml
Verify that CloudNatvicePG operator has created three pods: one primary and two standby.
kubectl get pods,svc -n demo
NAME READY STATUS RESTARTS AGE
pod/prod-1 1/1 Running 0 4m36s
pod/prod-2 1/1 Running 0 3m45s
pod/prod-3 1/1 Running 0 3m9s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prod-any ClusterIP 172.20.230.153 <none> 5432/TCP 4m54s
service/prod-r ClusterIP 172.20.33.61 <none> 5432/TCP 4m54s
service/prod-ro ClusterIP 172.20.96.16 <none> 5432/TCP 4m53s
service/prod-rw ClusterIP 172.20.236.1 <none> 5432/TCP 4m53s
The operator created also three services:
-rw: points only to the primary instances of cluster database-ropoints only to hot standby replicas for read-only-workloads-rpoints to any of the instances for read-only workloads
Note that -any points on all the instances.
Another way to check Cluster status is by using cloudnative-pg kubectl plugin offered by the CloudNativePG community,
kubectl cnpg status prod
Cluster Summary
Name: prod
Namespace: demo
System ID: 7214866198623563798
PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:15.2
Primary instance: prod-1
Status: Cluster in healthy state
Instances: 3
Ready instances: 3
Current Write LSN: 0/6000000 (Timeline: 1 - WAL File: 000000010000000000000005)
Certificates Status
Certificate Name Expiration Date Days Left Until Expiration
---------------- --------------- --------------------------
prod-ca 2023-06-24 14:40:27 +0000 UTC 89.96
prod-replication 2023-06-24 14:40:27 +0000 UTC 89.96
prod-server 2023-06-24 14:40:27 +0000 UTC 89.96
Continuous Backup status
First Point of Recoverability: Not Available
Working WAL archiving: OK
WALs waiting to be archived: 0
Last Archived WAL: 000000010000000000000005 @ 2023-03-26T14:52:09.24307Z
Last Failed WAL: -
Streaming Replication status
Replication Slots Enabled
Name Sent LSN Write LSN Flush LSN Replay LSN Write Lag Flush Lag Replay Lag State Sync State Sync Priority Replication Slot
---- -------- --------- --------- ---------- --------- --------- ---------- ----- ---------- ------------- ----------------
prod-2 0/6000000 0/6000000 0/6000000 0/6000000 00:00:00 00:00:00 00:00:00 streaming async 0 active
prod-3 0/6000000 0/6000000 0/6000000 0/6000000 00:00:00 00:00:00 00:00:00 streaming async 0 active
Unmanaged Replication Slot Status
No unmanaged replication slots found
Instances status
Name Database Size Current LSN Replication role Status QoS Manager Version Node
---- ------------- ----------- ---------------- ------ --- --------------- ----
prod-1 29 MB 0/6000000 Primary OK BestEffort 1.19.0 ip-10-1-10-192.us-west-2.compute.internal
prod-2 29 MB 0/6000000 Standby (async) OK BestEffort 1.19.0 ip-10-1-12-195.us-west-2.compute.internal
prod-3 29 MB 0/6000000 Standby (async) OK BestEffort 1.19.0 ip-10-1-11-38.us-west-2.compute.internal
Monitoring
In this example, we deployed a Prometheus and Grafana addons to monitor all database clusters created by CloudNativePG. Let's check Grafana dashboard.
kubectl -n monitoring port-forward svc/kube-prometheus-stack-grafana 8080:80
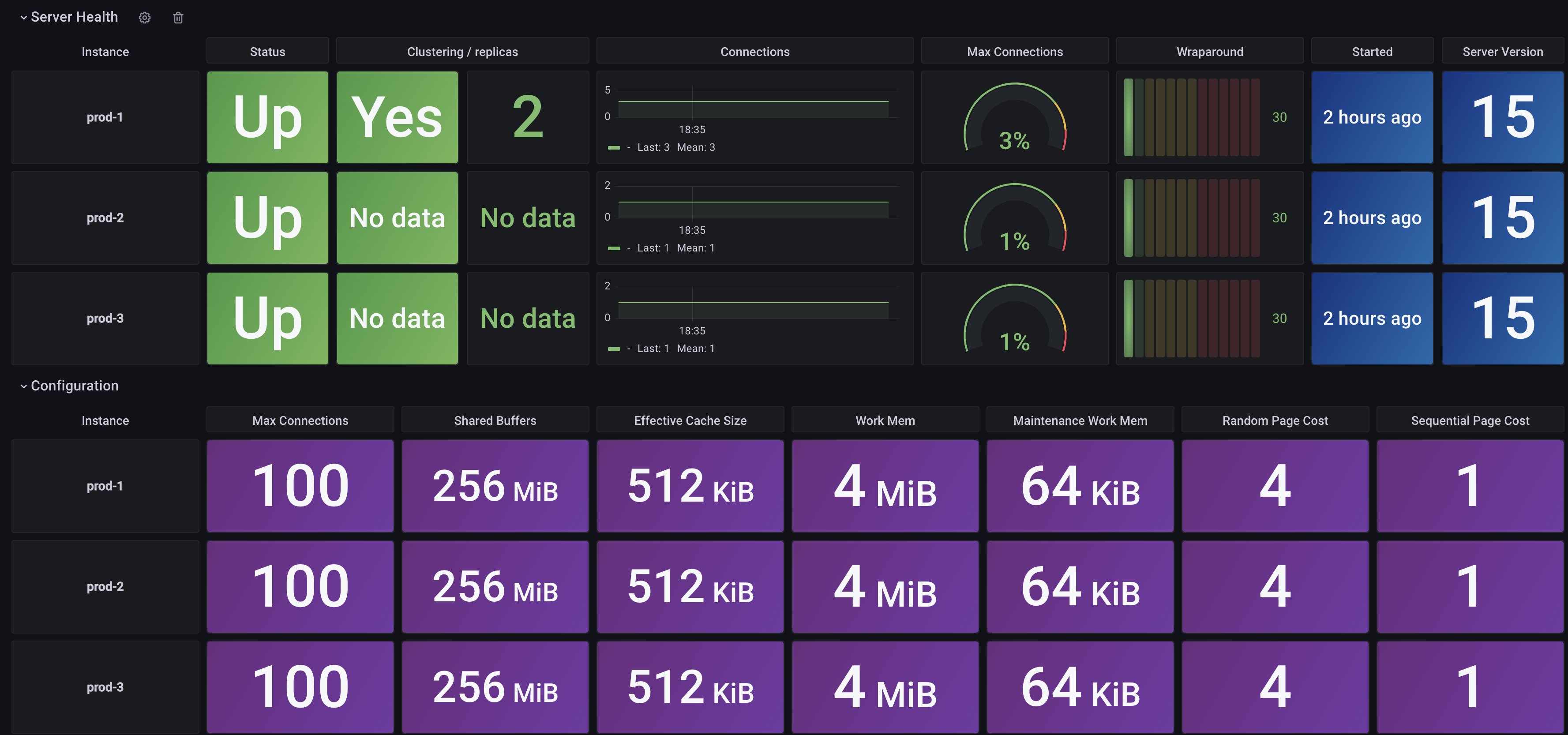
Import database sample
You can expose your database outside the cluster using ingress-controller or kubernetes service type LoadBalancer. However, for internal usage inside your EKS cluster, you can use kubernetes service prod-rw and prod-ro.
In this section, we are going to expose read-write service -rwusing kubectl port-forward.
kubectl port-forward svc/prod-rw 5432:5432 -n demo
Now, we use psql cli to import world.sql into our database instance WorldDB using credentials from app-auth secrets.
psql -h localhost --port 5432 -U app -d WorldDB < world.sql
# Quick check on db tables.
psql -h localhost --port 5432 -U app -d WorldDB -c '\dt'
Password for user app:
List of relations
Schema | Name | Type | Owner
--------+-----------------+-------+-------
public | city | table | app
public | country | table | app
public | countrylanguage | table | app
(3 rows)
Create Backup to S3
Now that we had a running database with data, CloudNativePG operator offers backup-restore feature using barman tool. CloudNativePG allows database admin to create on-demand database or Scheduled backups and for more details on documentations.
In this example, we will create a Backup object to start a backup process immediately.
apiVersion: postgresql.cnpg.io/v1
kind: Backup
metadata:
name: ondemand
spec:
cluster:
name: prod
kubectl create -f examples/backup-od.yaml
It will take couple minutes to run, then, check the backup process
kubectl describe backup ondemand
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Starting 60s cloudnative-pg-backup Starting backup for cluster prod
Normal Starting 60s instance-manager Backup started
Normal Completed 56s instance-manager Backup completed
Restore
For restore, we use bootstrap a new cluster using backup file on S3. The backup tool barman manages restore process, but, it doesn't support backup and restore for kubernetes secrets. This must be managed separately, like using csi-secrets-driver with AWS SecretsManager.
First let's delete prod database.
kubectl delete cluster prod -n demo
Then, update your template examples/cluster-restore.yaml with your S3 bucket and IAM role. Note that on restore template, CloudNativePG use externalClusters to point on the database.
kubectl create -f examples/cluster-restore.yaml
Type Reason Age From Message
---- ------ ---- ---- -------
Normal CreatingPodDisruptionBudget 7m12s cloudnative-pg Creating PodDisruptionBudget prod-primary
Normal CreatingPodDisruptionBudget 7m12s cloudnative-pg Creating PodDisruptionBudget prod
Normal CreatingServiceAccount 7m12s cloudnative-pg Creating ServiceAccount
Normal CreatingRole 7m12s cloudnative-pg Creating Cluster Role
Normal CreatingInstance 7m12s cloudnative-pg Primary instance (from backup)
Normal CreatingInstance 6m33s cloudnative-pg Creating instance prod-2
Normal CreatingInstance 5m51s cloudnative-pg Creating instance prod-3
When creating a new cluster, the operator will create a ServiceAccount with IRSA configuration as described on Cluster resources. Make sure the trust policy points the right ServiceAccount.
Let's check if the data were covered as expected.
psql -h localhost --port 5432 -U app -d WorldDB -c '\dt'
Password for user app:
List of relations
Schema | Name | Type | Owner
--------+-----------------+-------+-------
public | city | table | app
public | country | table | app
public | countrylanguage | table | app
(3 rows)
psql -h localhost --port 5432 -U app -d WorldDB -c 'SELECT CURRENT_TIME;'
Conclusion
CloudNativePG operator provides Level 5 from Operator Capability Levels. In this example, we share a blueprint that deploy the operator as an addon along with its monitoring stack (Prometheus and grafana). Among many features, we highlighted couple of examples on creating cluster, importing data and restoring database in case of disaster (or cluster deletion). More features are available on this documentation